This is part 2 of my series on how to deploy a Ruby on Rails application to AWS. If you found this page via search, I recommend starting from the beginning.
Recap of last step and overview of this step
In the previous step we launched an EC2 instance.
In this step we’re going to install some useful software on our new EC2 instance, specifically web server software.
A note before diving in: I must give credit to Passenger docs, from which some of this is directly lifted.
1. Install nginx
The very first step is to install nginx, which luckily involves very few steps.
As a reminder, these commands and all commands that follow are meant to be run on your new EC2 instance. Instructions for how to SSH into your EC2 instance can be found near the end of the previous step.
sudo apt-get update
sudo apt-get install -y nginx
sudo service nginx restart
2. Install Passenger
I recommend executing each of the following groups of commands separately, one at a time. That way it’s easier to tell whether each group of commands was successful or not.
sudo apt-get install -y dirmngr gnupg
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 561F9B9CAC40B2F7
sudo apt-get install -y apt-transport-https ca-certificates
sudo sh -c 'echo deb https://oss-binaries.phusionpassenger.com/apt/passenger bionic main > /etc/apt/sources.list.d/passenger.list'
sudo apt-get update
sudo apt-get install -y libnginx-mod-http-passenger
The following step verifies that the config files do in fact exist at /etc/nginx/conf.d/mod-http-passenger.conf. The result of the ls command is supposed to be the file path, printed back out to you (/etc/nginx/conf.d/mod-http-passenger.conf). If it’s not, there’s a problem.
if [ ! -f /etc/nginx/modules-enabled/50-mod-http-passenger.conf ]; then sudo ln -s /usr/share/nginx/modules-available/mod-http-passenger.load /etc/nginx/modules-enabled/50-mod-http-passenger.conf ; fi
sudo ls /etc/nginx/conf.d/mod-http-passenger.conf
Now we’ll restart nginx to make our changes take effect.
sudo service nginx restart
This step validates the Passenger installation.
sudo /usr/bin/passenger-config validate-install
3. Configure nginx/Passenger to know about Ruby
What follows in this step is roughly copied from this page. If you have trouble or want clarification, I recommend visiting that page to get the info directly from its original source.
The first thing we need to do is find out our Ruby path. Running the following command will tell us. You’ll probably have to look kind of hard because the output of the command is “noisy”. The Ruby path is there but it’s kind of obscured by some other stuff.
passenger-config about ruby-command
Once you’ve found the Ruby path in the output of that command, copy it. We now need to edit /etc/nginx/sites-enabled/default. I use Vim but you can of course use whatever editor you want.
sudo vi /etc/nginx/sites-enabled/default
We’ll need to add the following two lines inside the server block. I don’t believe it matters exactly where these two lines go as long as they’re between the two braces of the server block.
passenger_enabled on;
passenger_ruby /usr/bin/ruby2.5; # Note: your Ruby path may be different
If it helps, here’s what my complete /etc/nginx/sites-enabled/default looks like (with comments removed for brevity):
server {
listen 80 default_server;
listen [::]:80 default_server;
root /var/www/html;
index index.html index.htm index.nginx-debian.html;
server_name _;
# Important: delete the following 3 lines
# location / {
# try_files $uri $uri/ =404;
# }
passenger_enabled on;
passenger_ruby /usr/bin/ruby2.5;
}
Now we’ll restart nginx to make our changes take effect.
sudo service nginx restart
4. Enable port 80 to allow web traffic
Our server is now ready to be visited in the browser, except by default AWS doesn’t have port 80 open, the port for HTTP traffic. Let’s open port 80.
The way we do this is by adding a rule for port 80 to our EC2 instance’s security group.
To do this, first go to to the AWS console, click the EC2 instance, make sure you’re on the Description tab, then click the first link under Security groups.
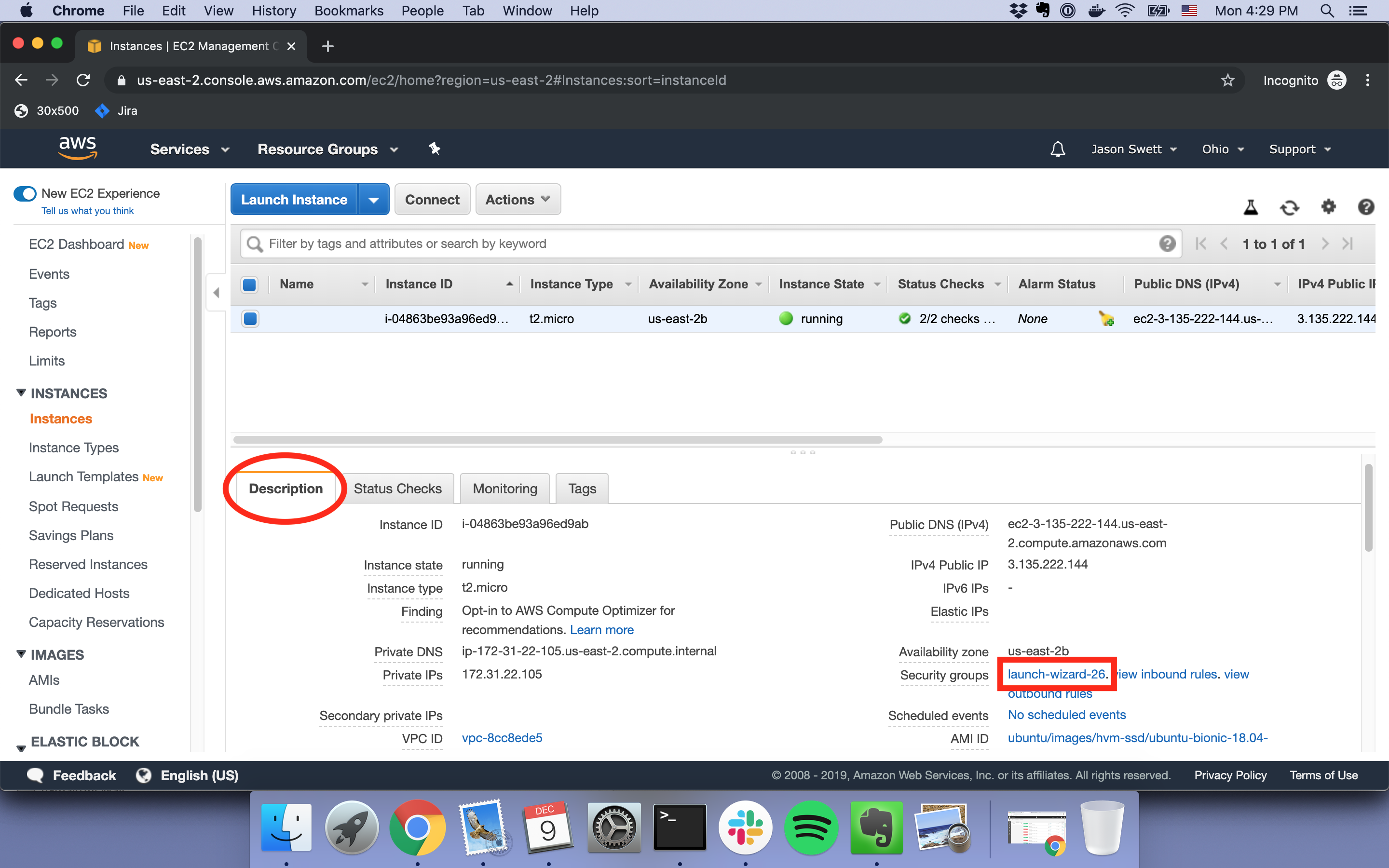
Then, under the Inbound tab, click Edit.
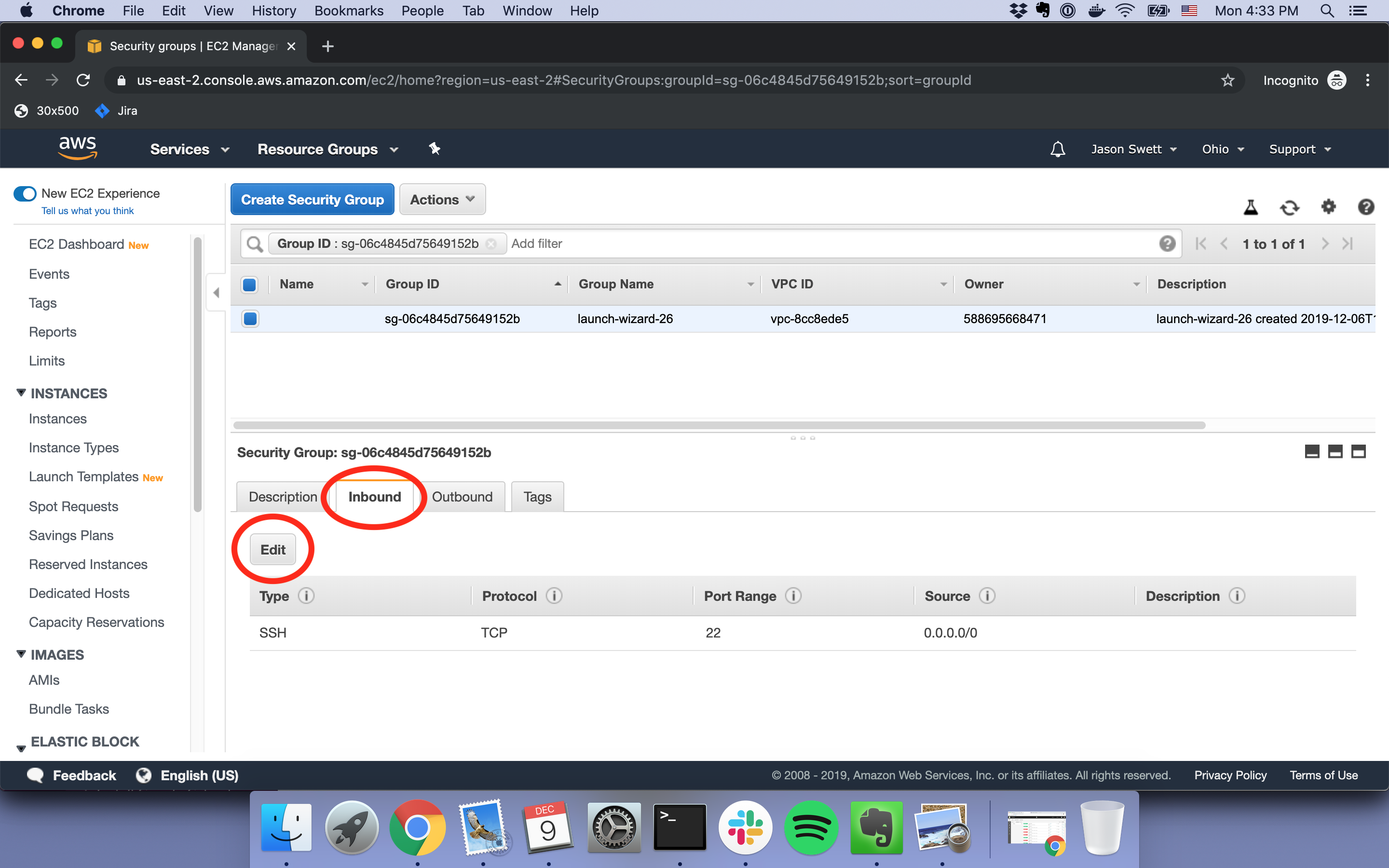
Click Add Rule, select HTTP from the list, then click Save. The change will take effect right away and HTTP traffic will be allowed starting immediately.
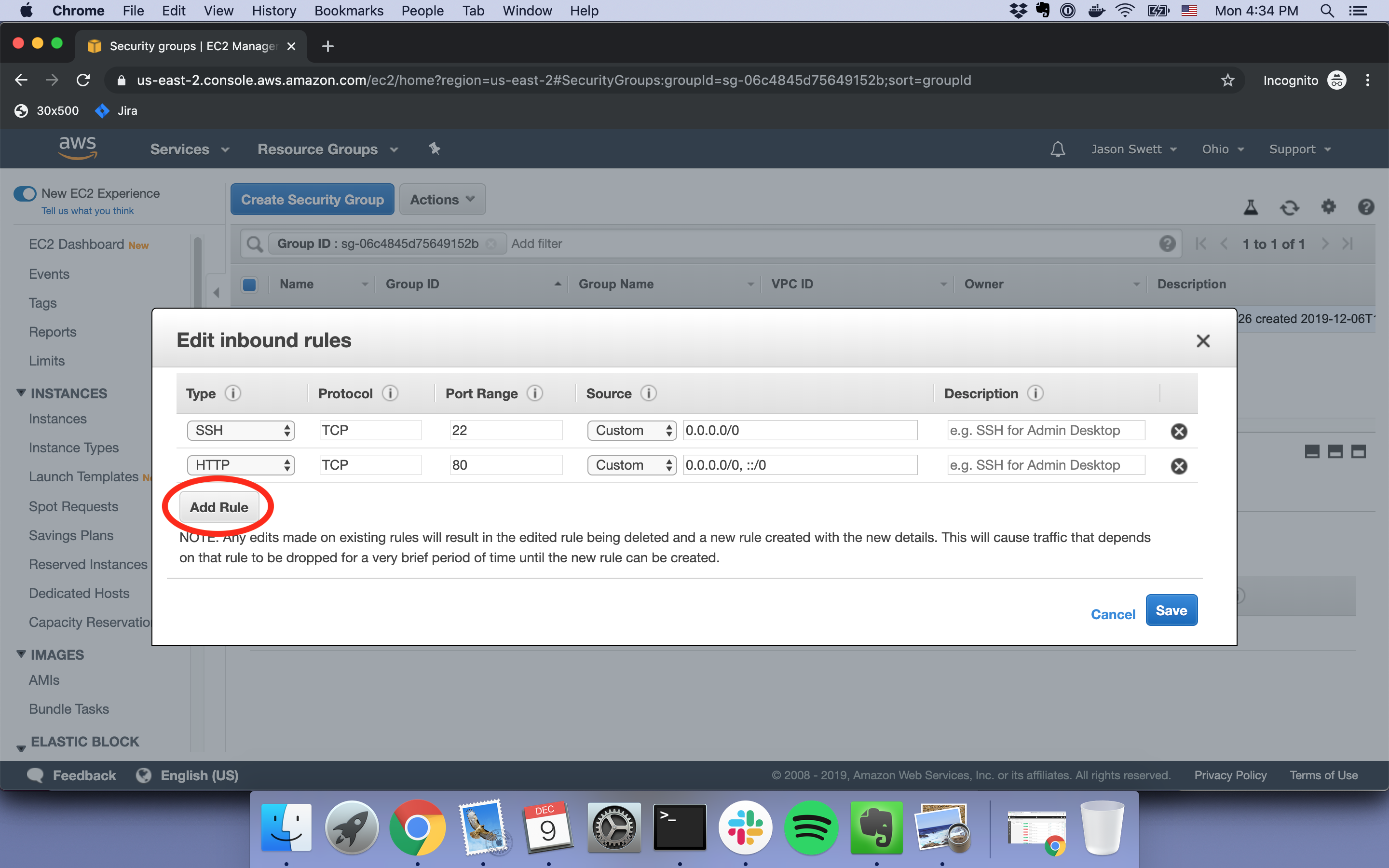
5. Visit the server in the browser
Enter your EC2 instance’s public DNS into your browser. As a reminder, this can be done by going to the EC2 Dashboard, right-clicking your instance, and clicking Connect.
When you visit your server you should see the following page. This means nginx is running!
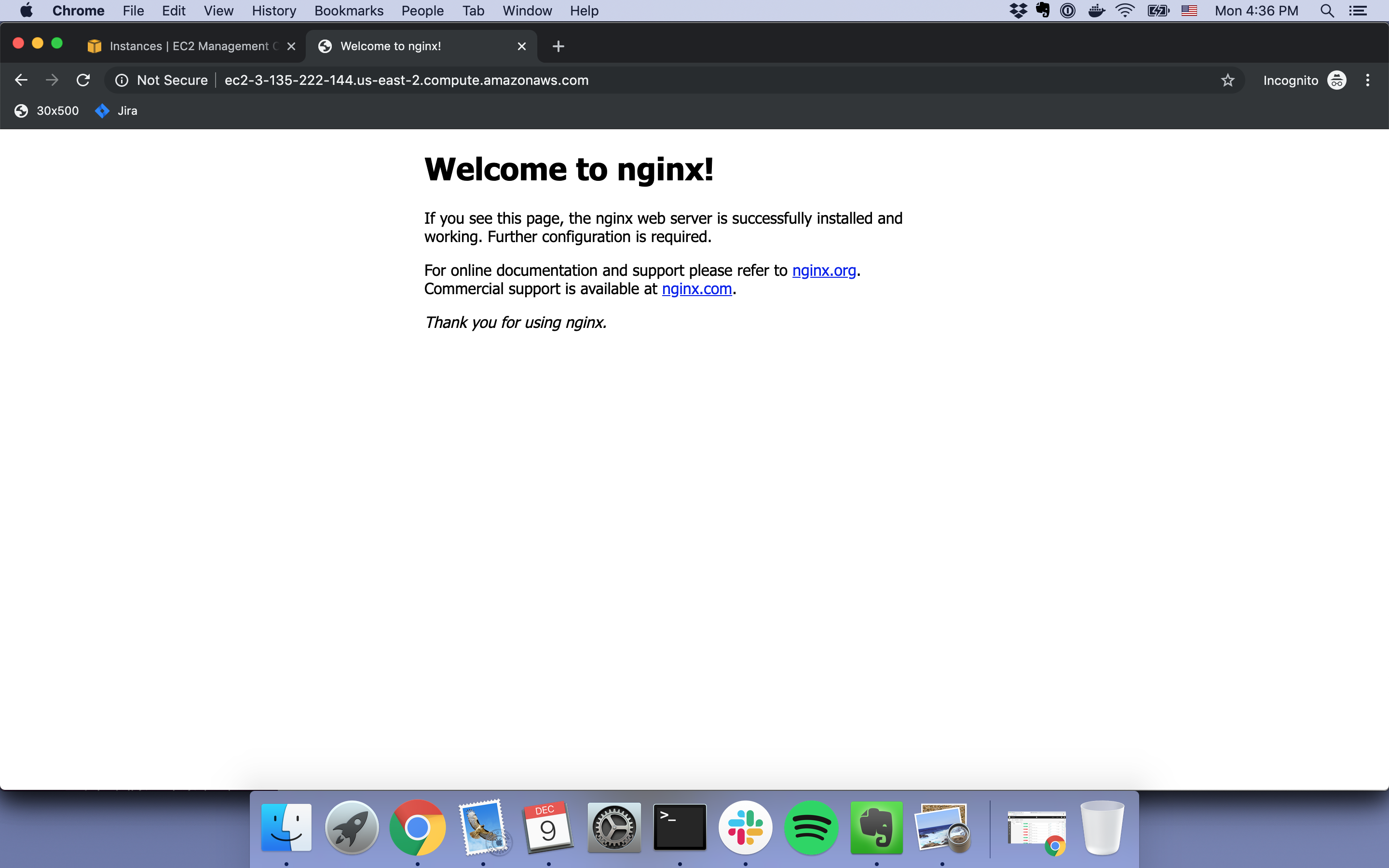
Now we can move onto the next step, connecting Rails with nginx.
[xyz-ihs snippet=”rails-tips-opt-in”]