What this post covers
In this post I’m going to show what could be considered a “hello world” of Ansible + AWS, using Ansible to launch an EC2 instance.
Aside from the time required to set up an AWS account and install Ansible, you should be able to get your EC2 instance running in 20 minutes or less.
Why Ansible + AWS for Rails hosting?
AWS vs. Heroku
For hosting Rails applications, the service I’ve reached for the most in the past is Heroku.
Unfortunately it’s not always possible or desirable to use Heroku. Heroku can get expensive at scale. There are also sometimes legal barriers due to e.g. HIPAA.
So, for whatever reason, AWS is sometimes a more viable option than Herokou.
The challenges with AWS + Rails
Unfortunately once you leave Heroku and enter the land of AWS, you’re largely on your own in many ways. Unlike with Heroku, there’s not one single way to do your deployment. There are basically infinite possible ways.
One way is to deploy manually, but that has all the disadvantages you can imagine a manual solution would have, such as, most obviously, a bunch of manual work to do each time you deploy.
Another option is to use Elastic Beanstalk. Elastic Beanstalk is kind of like AWS’s answer to Heroku, but it’s not nearly as nice as Heroku, and customizations can be a little tricky/hacky.
The advantages of using Ansible
I’ve been using Ansible for the last several months both on a commercial project and for my own personal projects.
If you’re not familiar with Ansible, here’s a description from the docs: “Ansible is an IT automation tool. It can configure systems, deploy software, and orchestrate more advanced IT tasks such as continuous deployments or zero downtime rolling updates.”
Ansible is often seen mentioned with similar tools like Puppet and Chef. I went with Ansible because among Ansible, Puppet, and Chef, Ansible had documentation that I could actually comprehend.
I’ve personally been using Ansible for two things so far: 1) provisioning EC2 instances and 2) deploying my Rails application. When I say “provisioning” I mainly mean spinning up an EC2 instance and installing all the software on it that my Rails app needs, like PostgreSQL, Bundler, Yarn, etc.
I like using Ansible because it allows me to manage my infrastructure using (at least to an extent so far) infrastructure as code. Rather than e.g. manually installing PostgreSQL and Bundler each time I provision a new EC2 instance, I write playbooks comprised of tasks (playbook and task are Ansible terms) that say things like “install Postgresql” and “install the Bundler gem”. This makes the cognitive burden of maintenance way lower and it also makes my infrastructure setup less of a black box.
Instructions for provisioning an EC2 instance
Before you start you’ll need to have Ansible installed and of course have an AWS account available for use.
For this exercise we’re going to create two files. The first will be an Ansible playbook in a file called launch.yml which can be placed anywhere on your filesystem.
The launch playbook
Copy and paste from the content below into a file called launch.yml placed, again, wherever you want.
Make careful note of the region entry. I use us-west-2, so if you use that region also, you’ll need to make sure to look for your EC2 instance in that region and not in another one.
Also make note of the image entry. I believe EC2 images can vary from region to region, so make sure that the image ID you use does in fact exist in the region you use.
Lastly, replace my_ssh_key_name with the full path to whatever SSH key you normally use to SSH into your EC2 instances, for example, ~/.ssh/aws-key.
---
- hosts: localhost
gather_facts: false
vars_files:
- vars.yml
tasks:
- name: Provision instance
ec2:
aws_access_key: "{{ aws_access_key }}"
aws_secret_key: "{{ aws_secret_key }}"
key_name: my_ssh_key_name
instance_type: t2.micro
image: ami-0d1cd67c26f5fca19
wait: yes
count: 1
region: us-west-2The vars file
Rather than hard-coding the entries for aws_access_key and aws_secret_key, which would of course be a bad idea if we were to commit our playbook to version control, we can have a separate file where we keep secret values. This separate file can either be added to a .gitignore or managed with something called Ansible Vault (which is outside the scope of this post).
Create a file called vars.yml in the same directory where you put launch.yml. This file will only need the two lines below. You’ll of course need to replace my placeholder values with your real AWS access key and secret key.
---
aws_access_key: XXXXXXXXXXXXXXXX
aws_secret_key: XXXXXXXXXXXXXXXXThe launch command
With our playbook and vars file in place, we can now run the command to execute the playbook:
$ ansible-playbook -v launch.ymlYou’ll probably see a couple warnings including No config file found; using defaults and [WARNING]: No inventory was parsed, only implicit localhost is available. These are normal and can be ignored. In many use cases for Ansible, we’re running our playbooks against remote server instances, but in this case we don’t even have any server instances yet, so we’re just running our playbook right on localhost. For whatever reason Ansible feels the need to warn us about this.
Verification
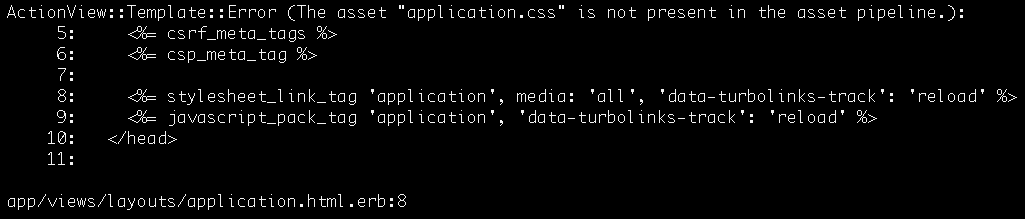
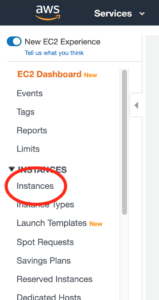
If you now open up your AWS console and go to EC2, you should now be able to see a fresh new EC2 instance.
To me this sure beats manually clicking through the EC2 instance launch wizard.
Good luck, and if you have any troubles, please let me know in the comments.
[xyz-ihs snippet=”rails-tips-opt-in”]