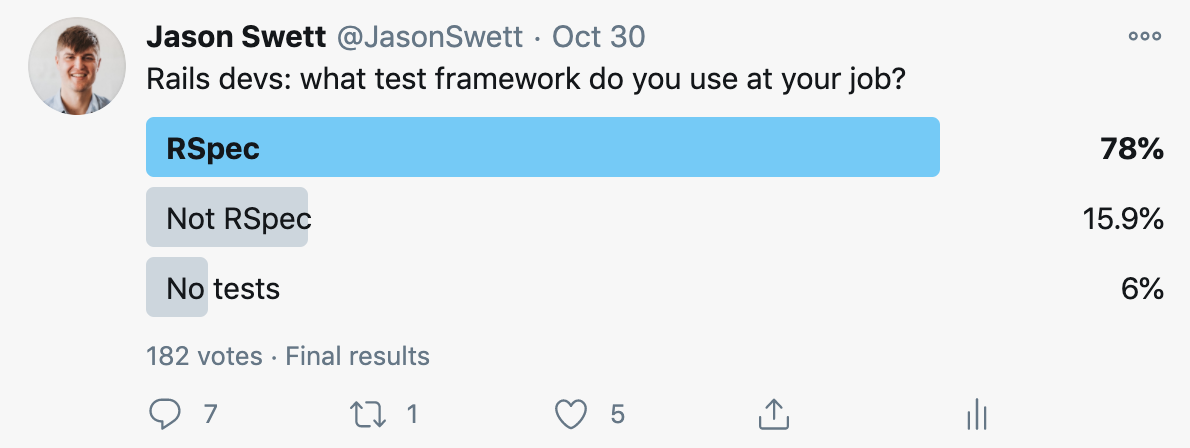
When starting out with Rails testing, it’s hard to know where to start.
First, there’s the decision of which framework to use. Then, if you’ve chosen RSpec (which most people do), you’re presented with a bewildering set of possible test types to use.
In this post I’ll show you what types of tests there are. I’ll show you which ones you should use and which ones you can ignore. Since most commercial Rails projects use RSpec, I’m going to focus on the eight types of tests that the RSpec library offers. (Although if I were to use Minitest, my strategy regarding test types would be pretty much the same.)
The eight types of RSpec specs
The RSpec library offers a lot of different spec types.
- Model specs
- System specs/feature specs*
- Request specs/controller specs*
- Helper specs
- View specs
- Routing specs
- Mailer specs
- Job specs
There are two lines with asterisks. These are cases where the RSpec team decreed one spec type obsolete and replaced it with a new type. I’m only including those ones for completeness.
So the up-to-date list is really the following.
- Model specs
- System specs
- Request specs
- Helper specs
- View specs
- Routing specs
- Mailer specs
- Job specs
Here’s when I use each.
- Model specs – always
- System specs – always
- Request specs – rarely
- Helper specs – rarely
- View specs – never
- Routing specs – never
- Mailer specs – never
- Job specs – never
Let’s talk about each of these spec types in detail. I’ll explain why I use the ones I use and why I ignore the ones I ignore.
Spec types I always use
Believe it or not, the overwhelming majority of the Rails tests I write make use of just two of the eight different spec types offered by RSpec. You might think that this would leave large gaps in my test coverage but it doesn’t. My test coverage is consistently above 95%.
System specs
System specs are “high-level” tests that simulate a user’s keystrokes and mouse clicks. System specs literally open up a browser window (although perhaps an invisible browser window if the tests are run “headlessly”) and use certain tools to manipulate the browser to exercise your application through simulated user input.
The reason I find system specs so valuable is that they test my whole stack, not just a slice of it, and they test my application in the same exact way that a real user will be using it. System specs are the only type of test that give me confidence my whole application really works.
I write so many system specs that I’ve developed a repeatable formula for adding system specs to any new CRUD feature.
Model specs
Even though system specs are indispensable, they’re not without drawbacks. System specs are somewhat “heavy”. They’re often more work to write and more expensive to run than other types of tests. For this reason I like to cover my features with a small number of coarse-grained system specs and a comparatively large number of fine-grained model specs.
As the name implies, model specs are for testing models. I tend to only bring model specs into the picture once a model has reached a certain level of “maturity”. At the beginning of a model’s life, it might have all its needs covered by built-in Rails functionality and not need any methods of its own. Some people write tests for things like associations and validations but I don’t because I find those types of tests to be pointless.
I use model specs to test my models’ methods. When I do so, I tend to use a test-first approach and write a failing test before I add a new line of code so that I’m sure every bit of code in my model is covered by a test.
Spec types I rarely use
Request specs
Request specs are more or less a way to test controller actions in isolation. I tend not to use request specs much because in most cases they would be redundant to my system specs. If I have system specs covering all my features, then of course a broken controller would fail one or more of my tests, making tests specifically for my controllers unnecessary.
I also try to keep my controllers sufficiently simple as to not call for tests of their own.
There are just three scenarios in which I do use request specs. First: If I’m working on a legacy project with fat controllers, sometimes I’ll use request specs to help me harness and refactor all that controller code. Second: If I’m working on an API-only Rails app, then system specs are physically impossible and I drop down to request specs instead. Lastly, if it’s just too awkward or expensive to use a system spec in a certain case then I’ll use a request spec instead. I write more about my reasoning here.
Helper specs
The reason I rarely write helper specs is simple: I rarely write helpers.
Spec types I never use
View specs and routing specs
I find view specs and routing specs to be redundant to system specs. If something is wrong with one of my views or routes, it’s highly likely that one of my system specs will catch the problem.
Mailer specs and job specs
I don’t write mailer specs or job specs because I try very hard to make all my mailers and background jobs one-liners (or close). I don’t think mailers and background jobs should do things, I think they should only call things. This is because mailers and background jobs are mechanical devices, not code organization devices.
To test my mailers and background jobs, I put their code into a PORO model and write tests for that PORO.
Takeaways
RSpec offers a lot of different spec types but you can typically meet 98% of your needs with just system specs and model specs.
If you’re a total beginner, I’d suggest starting with system specs.
[xyz-ihs snippet=”rtmc-opt-in”]